

The Web as a Data Graph is a New Direction for SEO
Many of the articles that people writing about SEO are about to involve web pages and links between pages, but this post is about entities and relationships between entities and facts that are written about on web pages, and responses to queries from data graphs on the web about facts and attributes related to entities found on web pages. I recently came across a patent filing on the WIPO (World Intellectual Property Organization) site that I thought was worth writing about. The patent starts by telling us that it is about:
Large data graphs store data and rules that describe knowledge about the data in a form that provides for deductive reasoning.
The title for the patent tells us that it is ideally about submitting queries to a search engine in natural language (the way that people talk, and computers try to understand.)
The patent shows us an example, related to a data graph, entities, such as people, places, things, concepts, etc., which may be stored as nodes and the edges between those nodes may indicate the relationship between the nodes (facts that people can find out about those entities. In SEO, we are used to hearing about web pages and nodes and links between those pages as edges. This approach to entities is a different way of looking at nodes and edges, and we have most recently seen people talking about mentions of entities in place of links that mention pages. It is one way that SEO is moving forward to think about real-world objects such as entities when talking about a large database such as the web. The second patent from Google that (a provisional one) that I am aware of, was about facts and such a large database. I wrote about it in Google’s First Semantic Search Invention was Patented in 1999.
I wrote about a more recent patent at Google on how the search engine may read the web and extract entity information from it, and use the Web as a large scattered database. That post is Entity Extractions for Knowledge Graphs at Google. We have been seeing information online about pre-training programs such as BERT that can tag words in a document with parts of speech and identify and recognize entities, so that they can be extracted from pages, and learned about by the search engine.
This newest patent tells us that in such a data graph, nodes such as “Maryland” and “United States” could be linked by the edges of “in-country” and/or “has state.”
We are also told that the basic unit of such a data graph is a tuple that includes two entities and a relationship between the entities.
Those tuples may represent real-world facts, such as “Maryland is a state in the United States.”
The tuple may also include other information, such as context information, statistical information, audit information, etc.
The process of adding entities and relationships to a data graph has typically been a manual process, making the creation of large data graphs difficult and slow.
And the difficulty in creating large data graphs can result in many “missing” entities and “missing” relationships between entities that exist as facts but have not yet been added to the graph.
Such missing entities and relationships reduce the usefulness of querying the data graph.
Some implementations extract syntactic and semantic knowledge from text, such as from the Web, and combine this with semantic knowledge from a data graph.
Building Confidence About Relationships Between Entities and Facts
Association Scores measure confidence in relationships between multiple entities, between entities & attributes for those entities, & between entities & classifications for those entities. These are generated when Google extracts entity information from text on the Web. 1/2
— Bill Slawski ⚓ (@bill_slawski) June 25, 2020
The knowledge extracted from the text and the data graph is used as input to train a machine-learning algorithm to predict tuples for the data graph.
The trained machine learning algorithm may produce multiple weighted features for a given relationship, each feature representing an inference about how two entities might be related.
The absolute value of the weight of a feature may represent the relative importance in making decisions. Google has pointed out in other patents that they are measuring confidence between such relationships and are calling those weight “association scores.”
The trained machine learning algorithm can then be used to create additional tuples from a data graph from analysis of documents in a large corpus and the existing information in the data graph.
This method provides a large number of additional tuples for the data graph, greatly expanding that data graph.
In some implementations, each predicted tuple may be associated with a confidence score and only tuples that meet a threshold are automatically added to the data graph.
The facts represented by the remaining tuples may be manually verified before being added to the data graph.
Some implementations allow natural language queries to be answered from the data graph.
The machine learning module can be trained to map features to queries, and the features being used to provide possible query results.
The training may involve using positive examples from search records or query results obtained from a document-based search engine.
The trained machine learning module may produce multiple weighted features, where each feature represents one possible query answer, represented by a path in the data graph.
The absolute value of the weight of the feature represents the relative importance in making decisions.
Once the machine learning module has been properly trained with the multiple weighted features it can be used to respond to natural language queries using information from the data graph.
A computer-implemented method includes receiving a machine learning module trained to produce a model with multiple weighted features for a query, each weighted feature representing a path in a data graph.
The method also includes receiving a search query that includes a first search term, mapping the search query to the query, mapping the first search term to a first entity in the data graph, and identifying a second entity in the data graph using the first entity and at least one of the multiple weighted features.
The feature may also include providing information relating to the second entity in a response to the search query.
The query may be a natural language query.
As another example, the method may include training the machine learning model to produce the model, which is the focus of this patent.
Obtaining Search Results From Natural Language Queries From a Data Graph
Training the machine learning module may include generating noisy query answers and generating positive and negative training examples from the noisy query answers.
Generating the noisy query answers may include obtaining search results from a search engine for a document corpus, each result having a confidence score and generating the training examples can include selecting a predetermined number of highest scored documents as positive training examples and selecting a predetermined number of documents with a score below a threshold as negative training examples.
Obtaining search results can include reading search results from search records for past queries.
Generating positive and negative training examples can include performing entity matching on the query answers and selecting entities that occur most often as positive training examples.
The method may also include determining a confidence score (like the association scores referred to above) for the second entity based on the weight of at least one weighted feature.
Identifying the second entity in the graph may also include selecting the second entity based on the confidence score and determining the confidence score for the second entity may include determining that two or more features connect to the second entity and using a combination of the weights of the two or more features as the confidence score for the second entity.
A computer-implemented method includes training a machine learning module to create multiple weighted features for a query and receiving a request for the query.
The method also includes determining a first entity from the request for the query, the first entity existing in a data graph having entities and edges, and providing the first entity and the query to the machine learning module.
This method may also include receiving a subset of the multiple weighted features from the machine learning module; and generating a response to the request that includes information obtained using the subset of the multiple weighted features.
These can include one or more of the following features. For example training the machine learning module can include:
- Selecting positive examples and negative examples from the data graph for the query
- Providing the positive examples, the negative examples, and the data graph to the machine learning module for training
- Receiving the multiple weighted features from the machine learning module, each feature representing a walk in the data graph
- Storing at least some of the multiple weighted features in a model associated with the query
Some of the features that this process will follow can include limiting a path length for the features to a predetermined length, the path length is the number of edges traversed in the path for a particular feature, and/or the positive and negative examples are generated from the search records for a document-based search engine.
The multiple weighted features may exclude features occurring less than a predetermined number of times in the data graph.
Generating the response to the query can include determining a second entity in the data graph with the highest weight and including information from the second entity in the response.
The weight of the second entity can be the sum of the weight of each feature associated with the second entity. The query can represent a cluster of queries.
Also, a computer system can include memory storing a directed edge-labeled data graph constructed using tuples, where each tuple represents two entities linked by a relationship, at least one processor, and memory storing instructions that, when executed by at least one processor, can cause the computer system to perform operations.
Those operations can include:
- Receiving query
- Generating query answers for the query
- Generating positive and negative training examples from the query answers
- Providing the positive examples, the negative examples, and the data graph to a machine learning module for training
The operations may also include receiving a plurality of features from the machine learning module for the query and storing the plurality of features as a model associated with the query in the machine learning module.
The following features should be used such as the features being weighted features and the query being a natural language query.
The number of features can also exclude features that occur less than a predetermined number of times in the data graph and features with a probability of reaching a correct target that falls below a predetermined threshold.
As part of generating query answers, the instructions, when executed by the at least one processor, can:
- Cause the computer system to identify a query template for the query
- Examine search records for queries matching the query template
- Obtain search results from the search records for queries matching the query template
As part of generating positive and negative training examples, the instructions:
- Cause the computer system to extract a source entity from a query in the search records that matches the query template
- Extract entities from the search results of the query that matches the query template
- Determine the number of times a target entity appears in the search results of the query that matches the query template
- Use the source entity and the target entity as a positive training example if the number of times meets a hreshold
The features may be weighted.
Each of the features can have its own associated weight.
A feature can be a path through the data graph with an associated confidence score. The path may represent a sequence of edges in the data graph.
The patent tells us about the following advantages from using the process in the Querying Data Graph patent
- Implementations may automatically extend a data graph by reading relational information from a large text corpus, such as documents available over the Internet or other corpora with more than a million documents, and combine this information with existing information from the data graph
- Such implementations can create millions of new tuples for a data graph with high accuracy
- Some implementations may also map natural language queries to paths in the data graph to produce query results from the data graph
- One difficulty with natural language queries is finding a match between the relationships or edges in the data graph to the query
- Some implementations train the machine learning module to perform the mapping, making natural language querying of the graph possible without a manually entered synonym table that can be difficult to exhaustively populate, maintain and verify
This patent can be found here:
Querying a Data Graph Using Natural Language Queries
Inventors Amarnag Subramanya, Fernando Pereira, Ni Lao, John Blitzer, Rahul Guptag
Applicants GOOGLE LLC
US20210026846
Patent Filing Date October 13, 2020
Patent Number 20210026846
Granted: January 28, 2021
Abstract
Implementations include systems and methods for querying a data graph. An example method includes receiving a machine learning module trained to produce a model with multiple features for a query, each feature representing a path in a data graph.
The method also includes receiving a search query that includes a first search term, mapping the search query to the query, and mapping the first search term to a first entity in the data graph.
The method may also include identifying a second entity in the data graph using the first entity and at least one of the multiple weighted features and providing information relating to the second entity in a response to the search query.
Some implementations may also include training the machine learning module by, for example, generating positive and negative training examples from an answer to a query.
Understanding a Data Graph Better
A syntactic-semantic inference system as described in the patent with an example implementation.
This system could be used to train a machine learning module to recognize multiple weighted features, or walks in the data graph, to generate new tuples for the data graph based on information already in the graph and/or based on parsed text documents, as I examine in the Entity Extraction patent I linked to above or another patent on Knowledge graph reconciliation that I have also written about.
The system can work to generate search results from the data graph from a natural language query.
This patent describes a system that would use documents available over the Internet.
But, we are told that other configurations and applications may be used.
These can include documents originating from another document corpus, such as internal documents not available over the Internet or another private corpus, from a library, from books, from a corpus of scientific data, or some other large corpus.
The syntactic-semantic inference system may be a computing device or device that takes the form of several different devices, for example, a standard server, a group of such servers, or a rack server system.
The syntactic-semantic inference system may include a data graph. The data graph can be a directed edge-labeled graph. Such a data graph stores nodes and edges.
The nodes in the data graph represent an entity, such as a person, place, item, idea, topic, abstract concept, concrete element, another suitable thing, or any combination of these.
Entities in the data graph may be related to each other by edges, which represent relationships between entities.
For example, the data graph may have an entity that corresponds to the actor Kevin Bacon and the data graph may have an acted in the relationship between the Kevin Bacon entity and entities representing movies that Kevin Bacon has acted in.
A data graph with a large number of entities and even a limited number of relationships may have billions of connections.
In some implementations, data graphs may be stored in an external storage device accessible from the system.
In some implementations, the data graph may be distributed across multiple storage devices and/or multiple computing devices, for example, multiple servers.
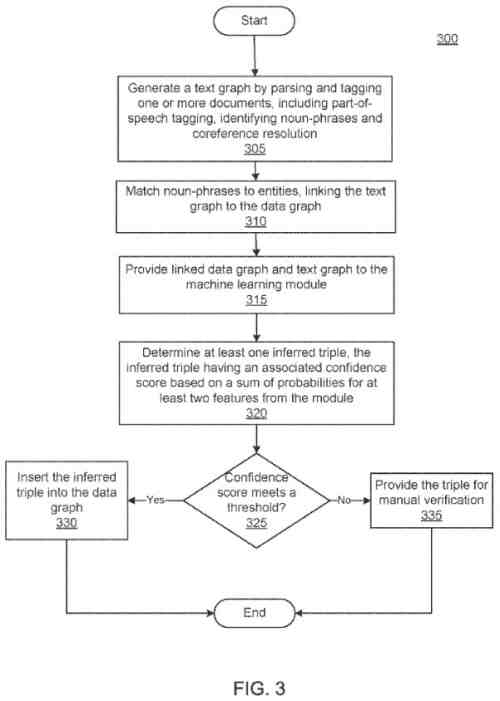
The patent goes on to provide more details about confidence scoring of facts, parts of speech tagging of words in a corpus, entity extraction.
It specifically looks at entities such as Miles Davis, John Coltrane, and New York and using coreference resolution to better understand pronouns in documents.
A text graph that might be generated according to the patent may also be linked to the data graph.
The patent tells us that linking may occur through entity resolution, or determining which entity from the data graph if any, matches a noun-phrase in a document.
We are returned to the idea of using mentions in SEO with statements like this from the patent:
Matches may receive a mention link between the entity and the noun phrase, as shown by links and 210′ of FIG. 2.
This is different from the links we see in HTML but is worth keeping an eye on. The patent tells us about the relationships between nodes and edges like this in a data graph:
Edge represents an edge from the data graph entity to the noun-phrase in the document. Edge′ represents the reverse edge, going from the noun-phrase to the entity.
Thus, as demonstrated in FIG. 2, the edges that link the data graph to the text graph may lead from the entity to the noun-phrase in a forward direction, and from the noun-phrase to the entity in a reverse direction.
Of course, forward Edge may have a corresponding reverse edge, and reverse Edge′ may have a corresponding forward edge, although these edges are not shown in the figure.
The patent describes the use of confidence scores and features weight for trusting in entities using queries like this one, where we are told about training using this system:
In some implementations, the training engine may be configured to use a text graph generated by the syntactic-semantic parsing engine from crawled documents that are linked to the data graph to generate training data for the machine learning module.
The training engine may generate the training data from random, path-constrained walks in the linked graph.
The random walks may be constrained by a path length, meaning that the walk may traverse up to a maximum number of edges.
Using the training data, the training engine may train a machine learning module to generate multiple weighted features for a particular relationship, or in other words to infer paths for a particular relationship.
A feature generated by the machine learning module is a walk-in-the-data graph alone or the combination of the data graph and text graph.
For instance, if entity A is related to entity B by edge t1, and B is related to entity C by edge t2, then A is related to C by the feature {t1, t2}.
The feature weight may represent confidence that the path represents a true fact.
The patent shows us a positive training example that teaches the machine learning algorithm to infer the profession of a person entity based on the professions of other persons mentioned in conjunction with the query person.
See the picture at the top of this blog post which includes people and mentions to professions of those people. The patent tells us that such a feature may appear as {Mention, conj, Mention −1, Profession}, where the Mentions represent the mentioned edge that links the data graph to the text graph, conj is an edge in the text graph, Mention −1 represents the mentioned edge that links the text graph to the data graph, and Profession is an edge in the data graph that links an entity for a person to an entity representing a profession.
We are then told in the patent:
If a person entity in the data graph is linked to a profession entity in the data graph by this path, or feature, the knowledge discovery engine can infer that the data graph should include a profession edge between the two entities.
The feature may have a weight that helps the knowledge discovery engine decide whether or not the edge should exist in the data graph.
We also learn of examples with the machine learning module being trained to map the queries for “spouse,” “wife,” “husband,” “significant other,” and “married to” to various paths in the data graph, based on the training data.
Those queries may be clustered, so that the machine learning module may be trained for a cluster of queries.
And the queries may refer to a cluster of queries with similar meanings.
The patent provides many examples of how a data graph about several entities can be learned from using examples like those above. Such training can then be used to answer queries from the data graph. The patent tells us that it can use information from sources other than the internet such as a document-based index and may combine the results from the data graph with the results from the document-based index.
This patent also has a large section on how Google may expand a data graph. The process sounds much like the one I described when I wrote about entity extraction which I linked to above. We are told that a data graph could involve learning from millions of documents.
The patent also has a section on associating inferred tuples with confidence scores using the Machine Learning module. It also tells us about checking the confidence score for the inferred tuples against a threshold
Purpose of Querying a Data Graph Using Natural Language Queires
This patent tells us about how a data graph could be created to identify entities and touples associated with those and build a data graph understanding confidence scores between those entities and facts related to them and understand similar entities with similar attributes, and use those Data Graphs to answer queries about all of those entities. A benefit from this approach would be that it could learn by reading the Web, and collecting information about entities and facts about them as it comes across them on the Web. I have summarized many aspects of the patent, and recommend reading through it to better learn about the details that it covers in more depth. I wanted to describe how it learns from the web it comes across and builds upon that knowledge so that it can answer queries that people ask.
I suspect that we will come across many more patents that describe related approaches that a search engine might use to better understand the world through what it reads.