
Calculating Featured Snippet Answer Scores
An update this week to a patent tells us how Google may score featured snippet answers.
When a search engine ranks search results in response to a query, it may use a combination of query dependant and query independent ranking signals to determine those rankings.
A query dependant signal may depend on a term in a query, and how relevant a search result may be for that query term. A query independent signal would depend on something other than the terms in a query, such as the quality and quantity of links pointing to a result.
Answers to questions in queries may be ranked based on a combination of query dependant and query independent signals, which could determine a featured snippet answer score. An updated patent about textual answer passages tells us about how those may be combined to generate featured snippet answer scores to choose from answers to questions that appear in queries.
A year and a half ago, I wrote about answers to featured snippets in the post Does Google Use Schema to Write Answer Passages for Featured Snippets?. The patent that the post was about was Candidate answer passages, which was originally filed on August 12, 2015, and was granted as a continuation patent on January 15, 2019.
That patent was a continuation patent to an original one about answer passages that updated it by telling us that Google would look for textual answers to questions that had structured data near them that included related facts. This could have been something like a data table or possibly even schema markup. This meant that Google could provide a text-based answer to a question and include many related facts for that answer.
Another continuation version of the first version of the patent was just granted this week. It provides more information and a different approach to ranking answers for featured snippets and it is worth comparing the claims in these two versions of the patent to see how those are different from Google.
The new version of the featured snippet answer scores patent is at:
Scoring candidate answer passages
Inventors: Steven D. Baker, Srinivasan Venkatachary, Robert Andrew Brennan, Per Bjornsson, Yi Liu, Hadar Shemtov, Massimiliano Ciaramita, and Ioannis Tsochantaridis
Assignee: Google LLC
US Patent: 10,783,156
Granted: September 22, 2020
Filed: February 22, 2018
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for scoring candidate answer passages. In one aspect, a method includes receiving a query determined to be a question query that seeks an answer response and data identifying resources determined to be responsive to the query; for a subset of the resources: receiving candidate answer passages; determining, for each candidate answer passage, a query term match score that is a measure of similarity of the query terms to the candidate answer passage; determining, for each candidate answer passage, an answer term match score that is a measure of similarity of answer terms to the candidate answer passage; determining, for each candidate answer passage, a query dependent score based on the query term match score and the answer term match score; and generating an answer score that is a based on the query dependent score.
Candidate Answer Passages Claims Updated
There are changes to the patent that require more analysis of potential answers, based on both query dependant and query independent scores for potential answers to questions. The patent description does provide details about query dependant and query independent scores. The first claim from the first patent covers query dependant scores for answers, but not query independent scores as the newest version does. It provides more details about both query dependant scores and query independent scores in the rest of the claims, but the newer version seems to make both query dependant and query independent scores more important.
The first claim from the 2015 version of the Scoring Answer Passages patent tells us:
1. A method performed by data processing apparatus, the method comprising: receiving a query determined to be a question query that seeks an answer response and data identifying resources determined to be responsive to the query and ordered according to a ranking, the query having query terms; for each resource in a top-ranked subset of the resources: receiving candidate answer passages, each candidate answer passage selected from passage units from content of the resource and being eligible to be provided as an answer passage with search results that identify the resources determined to be responsive to the query and being separate and distinct from the search results; determining, for each candidate answer passage, a query term match score that is a measure of similarity of the query terms to the candidate answer passage; determining, for each candidate answer passage, an answer term match score that is a measure of similarity of answer terms to the candidate answer passage; determining, for each candidate answer passage, a query dependent score based on the query term match score and the answer term match score; and generating an answer score that is a measure of answer quality for the answer response for the candidate answer passage based on the query dependent score.
The remainder of the claims tell us about both query dependant and query independent scores for answers, but the claims from the newer version of the patent appear to place as much importance on the query dependant and the query independent scores for answers. That convinced me that I should revisit this patent in a post and describe how Google may calculate answer scores based on query dependant and query independent scores.
The first claims in the new patent tell us:
1. A method performed by data processing apparatus, the method comprising: receiving a query determined to be a question query that seeks an answer response and data identifying resources determined to be responsive to the query and ordered according to a ranking, the query having query terms; for each resource in a top-ranked subset of the resources: receiving candidate answer passages, each candidate answer passage selected from passage units from content of the resource and being eligible to be provided as an answer passage with search results that identify the resources determined to be responsive to the query and being separate and distinct from the search results; determining, for each candidate answer passage, a query dependent score that is proportional to a number of instances of matches of query terms to terms of the candidate answer passage; determining, for each candidate answer passage, a query independent score for the candidate answer passage, wherein the query independent score is independent of the query and query dependent score and based on features of the candidate answer passage; and generating an answer score that is a measure of answer quality for the answer response for the candidate answer passage based on the query dependent score and the query independent score.
As it says in this new claim, the answer score has gone from being “a measure of answer quality for the answer response for the candidate answer passage based on the query dependent score” (from the first patent) to “a measure of answer quality for the answer response for the candidate answer passage based on the query dependent score and the query independent score” (from this newer version of the patent.)
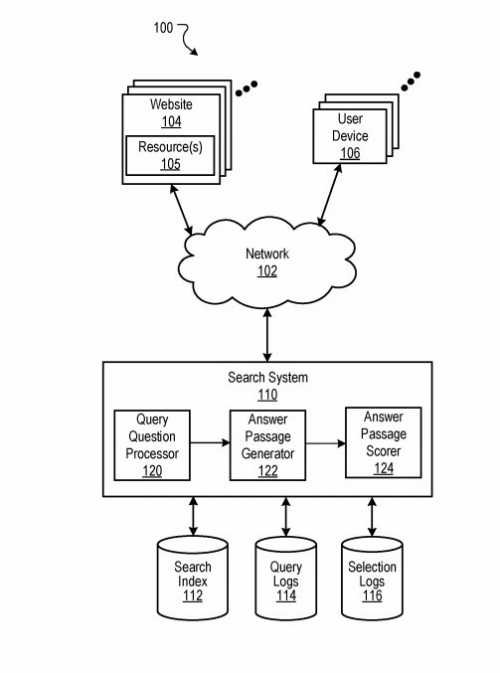
This drawing is from both versions of the patent, but it shows the query dependant and query independent scores both playing an important role in calculating featured snippet answer scores:

Query Dependant and Query Independent Scores for Featured Snippet Answer Scores
Both versions of the patent tell us about how a query dependant score and a query independent score for an answer might be calculated. The first version of the patent only told us in its claims that an answer score used the query dependant score, and this newer version tells us that both the query dependant and the query independent scores are combined to calculate an answer score (to decide which answer is the best choice of an answer for a query.)
Before the patent discusses how Query Dependant and Query Independent signals might be used to create an answer score, it does tell us this about the answer score:
The answer passage scorer receives candidate answer passages from the answer passage generator and scores each passage by combining scoring signals that predict how likely the passage is to answer the question.
In some implementations, the answer passage scorer includes a query dependent scorer and a query independent scorer that respectively generate a query dependent score and a query independent score. In some implementations, the query dependent scorer generates the query dependent score based on an answer term match score and a query term match score.
Query Dependant Scoring for Featured Snippet Answer Scores
Query Dependent Scoring of answer passages is based on answer term features.
An answer term match score is a measure of similarity of answer terms to terms in a candidate answer passage.
The answer-seeking queries do not describe what a searcher is looking for since the answer is unknown to the searcher at the time of a search.
The query dependent scorer begins by finding a set of likely answer terms and compares the set of likely answer terms to a candidate answer passage to generate an answer term match score. The set of likely answer terms is likely taken from the top N ranked results returned for a query.
The process creates a list of terms from terms that are included in the top-ranked subset of results for a query. The patent tells us that each result is parsed and each term is included in a term vector. Stop words may be omitted from the term vector.
For each term in the list of terms, a term weight may be generated for the term. The term weight for each term may be based on many results in the top-ranked subset of results in which the term occurs multiplied by an inverse document frequency (IDF) value for the term. The IDF value may be derived from a large corpus of documents and provided to the query dependent scorer. Or the IDF may be derived from the top N documents in the returned results. The patent tells us that other appropriate term weighting techniques can also be used.
The scoring process for each term of the candidate answer passage determines several times the term occurs in the candidate answer passage. So, if the term “apogee” occurs two times in a candidate answer passage, the term value for “apogee” for that candidate answer passage is 2. However, if the same term occurs three times in a different candidate answer passage, then the term value for “apogee” for the different candidate answer passage is 3.
The scoring process, for each term of the candidate answer passage, multiplies its term weight by the number of times the term occurs in the answer passage. So, assume the term weight for “apogee” is 0.04. For the first candidate answer passage, the value based on “apogee” is 0.08 (0.08.times.2); for the second candidate answer passage, the value based on “apogee” is 0.12 (0.04.times.3).
Other answer term features can also be used to determine an answer term score. For example, the query dependent scorer may determine an entity type for an answer response to the question query. The entity type may be determined by identifying terms that identify entities, such as persons, places, or things, and selecting the terms with the highest term scores. The entity time may also be identified from the query (e.g., for the query [who is the fastest man]), the entity type for an answer is “man.” For each candidate answer passage, the query dependent scorer then identifies entities described in the candidate answer passage. If the entities do not include a match to the identified entity type, the answer term match score for the candidate answer passage is reduced.
Assume the following candidate passage answer is provided for scoring in response to the query [who is the fastest man]: Olympic sprinters have often set world records for sprinting events during the Olympics. The most popular sprinting event is the 100-meter dash.
The query dependent scorer will identify several entities–Olympics, sprinters, etc.–but none of them are of the type “man.” The term “sprinter” is gender-neutral. Accordingly, the answer term score will be reduced. The score may be a binary score, e.g., 1 for the presence of the term of the entity type, and 0 for an absence of the term of the correct type; alternatively may be a likelihood that is a measure of the likelihood that the correct term is in the candidate answer passage. An appropriate scoring technique can be used to generate the score.
Query Independant Scoring for Featured Snippet Answer Scores
Scoring answer passages according to query independent features.
Candidate answer passages may be generated from the top N ranked resources identified for a search in response to a query. N may be the same number as the number of search results returned on the first page of search results.
The scoring process can use a passage unit position score. This passage unit position could be the location of a result that a candidate answer passage comes from. The higher the location results in a higher score.
The scoring process may use a language model score. The language model score generates a score based on candidate answer passages conforming to a language model.
One type of language model is based on sentence and grammar structures. This could mean that candidate answer passages with partial sentences may have lower scores than candidate answer passages with complete sentences. The patent also tells us that if structured content is included in the candidate answer passage, the structured content is not subject to language model scoring. For instance, a row from a table may have a very low language model score but may be very informative.
Another language model that may be used considers whether text from a candidate answer passage appears similar to answer text in general.
A query independent scorer accesses a language model of historical answer passages, where the historical answer passages are answer passages that have been served for all queries. Answer passages that have been served generally have a similar n-gram structure, since answer passages tend to include explanatory and declarative statements. A query independent score could use a tri-gram model to compares trigrams of the candidate answer passage to the tri-grams of the historical answer passages. A higher-quality candidate answer passage will typically have more tri-gram matches to the historical answer passages than a lower quality candidate answer passage.
Another step involves a section boundary score. A candidate answer passage could be penalized if it includes text that passes formatting boundaries, such as paragraphs and section breaks, for example.
The scoring process determines an interrogative score. The query independent scorer searches the candidate answer passage for interrogative terms. A potential answer passage that includes a question or question term, e.g., “How far is away is the moon from the Earth?” is generally not as helpful to a searcher looking for an answer as a candidate answer passage that only includes declarative statements, e.g., “The moon is approximately 238,900 miles from the Earth.”
The scoring process also determines discourse boundary term position scores. A discourse boundary term is one that introduces a statement or idea contrary to or modification of a statement or idea that has just been made. For example, “conversely,” “however,” “on the other hand,” and so on.
A candidate answer passage beginning with such a term receives a relatively low discourse boundary term position score, which lowers the answer score.
A candidate answer passage that includes but does not begin with such a term receives a higher discourse boundary term position score than it would if it began with the term.
A candidate answer passage that does not include such a term receives a high discourse boundary term position score.
The scoring process determines result scores for results from which the candidate answer passage was created. These could include a ranking score, a reputation score, and site quality score. The higher these scores are, the higher the answer score will be.
A ranking score is based on the ranking score of the result from which the candidate answer passage was created. It can be the search score of the result for the query and will be applied to all candidate answer passages from that result.
A reputation score of the result indicates the trustworthiness and/or likelihood that that subject matter of the resource serves the query well.
A site quality score indicates a measure of the quality of a web site that hosts the result from which the candidate answer passage was created.
Component query independent scores described above may be combined in several ways to determine the query independent score. They could be summed; multiplied together; or combined in other ways.
Added October 15, 2020 – I have written a few other posts about answer passages that are worth reading if you are interested in how Google finds questions on pages and answers to those, and scores answer passages to determine which ones to show as featured snippets. Here are those posts: