

As stated by Jeffrey Zhu, Program Manager of the Bing Platform in the article Bing delivers its largest improvement in search experience using Azure GPUs:
“Recently, there was a breakthrough in natural language understanding with a type of model called transformers (as popularized by Bidirectional Encoder Representations from Transformers, BERT) … Starting from April of this year, we used large transformer models to deliver the largest quality improvements to our Bing customers in the past year. For example, in the query “what can aggravate a concussion”, the word “aggravate” indicates the user wants to learn about actions to be taken after a concussion and not about causes or symptoms. Our search powered by these models can now understand the user intent and deliver a more useful result. More importantly, these models are now applied to every Bing search query globally making Bing results more relevant and intelligent.”

This chart from the PapersWithCode’s leaderboard for Question Answering, can show BERT significant contributions to the field.
Each point the chart represents a new state of the art record. You can see literally the progress before and after BERT.
Every subsequent record breaker adapts and improves on BERT’s original idea.

BERT performs really well for most natural language processing tasks, including question and answering.
The most shocking thing is that BERT and derivatives have been outperforming humans in both the SQUAD 2.0 (Stanford Question Question Answering dataset) and MS MARCO (A Human Generated MAchine Reading COmprehension Dataset) leaderboards since mid last year.
In order to fully understand its capabilities, let’s put BERT question answering capabilities to the test with some Python code.
Putting BERT Question Answering to the Test
Let’s write a bit of Python code to understand BERT better.
First download a Python distribution called Anaconda and Visual Studio Code and setup the Python bindings.
We are going to leverage Visual Studio Code built-in support for Jupyter notebooks. Alternatively, you can use a free Azure Notebook to run your code in the cloud.
Let’s create a new notebook by typing the keyword combination CTRL+Shift+P and selecting the option “Python Jupyter Notebook”.
After you create the notebook, let’s install the transformers library.
!pip install transformers
I get the version 2.4.1 at the time of this writing.
Next, we import a pipeline.
from transformers import pipeline
The HuggingFace team has done an amazing job with their transformers library and more recently with the pipeline feature that drastically simplifies the process of building transformer-based neural network models.
# Allocate a pipeline for question-answering
nlp = pipeline(‘question-answering‘)
This command downloads a BERT pipeline for question answering using the following default settings:
Pretrained weights: distilbert-base-cased-distilled-squad
Tokenizer: distilbert-base-cased
BERT is too large and slow to train and run on a PC or Mac. DistilledBERT is a faster and smaller version of BERT that we can run quickly. As it is the default option, we don’t need to provide any additional configuration.
Now, let’s test BERT question answering using an example from Hugging Face’s repository.
nlp({
‘question’: ‘What is the name of the repository ?’,
‘context’: ‘Pipeline have been included in the huggingface/transformers repository’
})
We provide both the question and the context (where the answer can be found).
convert squad examples to features: 100%|██████████| 1/1 [00:00
add example index and unique id: 100%|██████████| 1/1 [00:00
{‘answer’: ‘huggingface/transformers’,
‘end’: 59,
‘score’: 0.5135626548884602,
‘start’: 35}
With 3 simple lines of code we get a state of the art system that can answer questions given a context.
In addition to the answer, we can see three other results: the score or confidence in the answer and the starting and ending indices in the source context.
We can confirm the indices using this code.
context = ‘Pipeline have been included in the huggingface/transformers repository’
print(context[35:59])
We get this result.
huggingface/transformers
Testing BERT Question Answering on Your Content
Let’s download an article and extract the main content. We will use a CSS selector to scrape only the body of the post.
Let’s first install the requests-html library that will simplify downloading content.
!pip install requests-html
Then, we can download the article.
from requests_html import HTMLSession
session = HTMLSession()
url = “https://azure.microsoft.com/en-us/blog/bing-delivers-its-largest-improvement-in-search-experience-using-azure-gpus/”
selector = “#main > div > div.row.row-size2 > div.column.medium-8 > article > div:nth-child(1) > div.blog-postContent”
with session.get(url) as r:
post = r.html.find(selector, first=True)
text = post.text
These few lines of code extract the full text of the article and as you are probably guessing, that text will be the context we pass to our model.
Let’s test a few questions.
nlp({
‘question’: ‘How many Azure GPU Virtual Machines did the team use?’,
‘context’: text
})
Here is the answer and confidence.
{‘answer’: ‘2000+’, ‘end’: 4243, ‘score’: 0.9502126270466533, ‘start’: 4238}
Next one.
nlp({
‘question’: ‘When did Bing start using using BERT?’,
‘context’: text
})
Here is the answer and confidence.
{‘answer’: ‘April’, ‘end’: 1219, ‘score’: 0.3784087158489484, ‘start’: 1214}
Now a more complex question.
nlp({
‘question’: ‘Why even a distilled 3 layer model was still expensive to use?’,
‘context’: text
})
{‘answer’: ‘lower cost and regional availability.xa0’,
‘end’: 3132,
‘score’: 0.3492882736856018,
‘start’: 3094}
The correct answer is that it would require tens of thousands of servers just to ship one search improvement.
BERT is not perfect and there is still room for improvement. This opens opportunities for content writers to evaluate how the content structure changes could simplify the machine work. The work needed to deliver quality answers.
Why does BERT Answer Questions so Well?
In order to explain this, I need to introduce several building block concepts.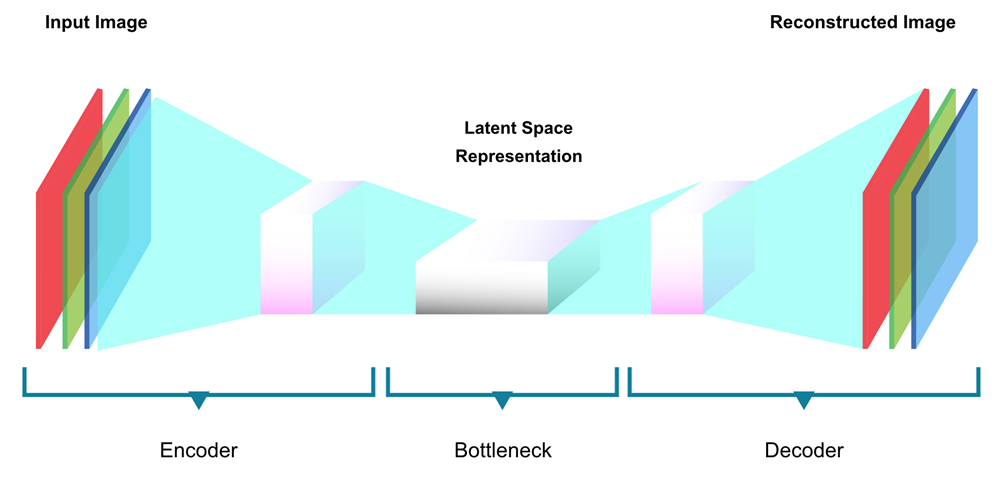
I’m going to use a very simple analogy to explain how natural language processing (NLP) works when you use deep learning.
Raw data (an image in the example above, but same happens with text) is encoded into a latent space and then the latent space representation is decoded into the expected transformation, which is also raw data.
In order to train a model to classify text or answer questions, we first need to encode the words into vectors, more specifically word embeddings.
These embeddings make up the latent space representation.
Once the words and/or phrases become vectors it is easy to cluster together similar concepts with simple proximity calculations.
As this is a very abstract concept, I’m going to use a GPS analogy to explain it in simple terms.
You can look up a business by its name in the physical world, or by its address or GPS coordinate.
When you look up a business by its name is like matching up Bing searches and content pages by the keywords typed.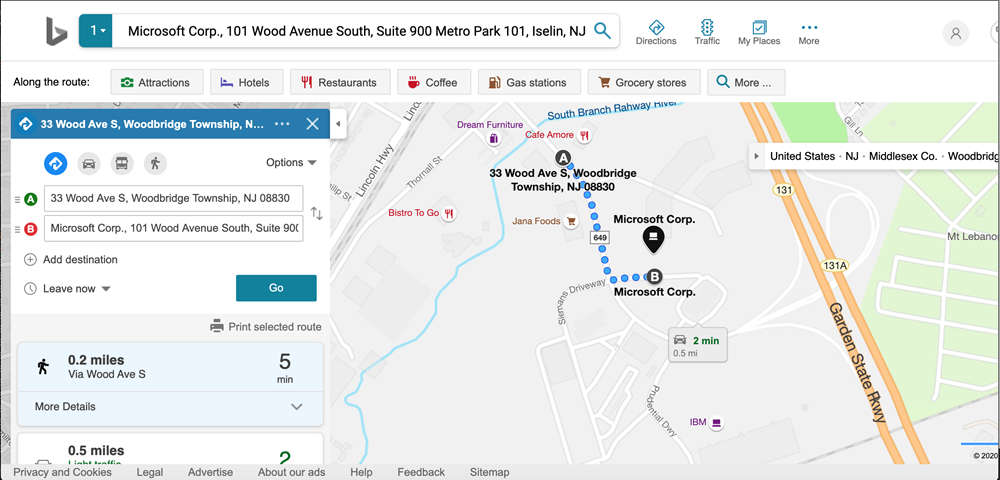
For example, Microsoft has an office in New Jersey that is a 5 minute walk from mine.
Their physical address in Iselin, NJ is 101 Wood Ave South. In Spanish, it is 101 avenida Wood sur. In Korean 101 우드 애비뉴 사우스. If you are walking by, you could refer to it in terms of the number of blocks and turns.
In other words, we refer to the same place in different ways. But, computers need a universal way to refer to things that are context independent.
One simple approach is to build a simple index where each word gets a number. That is similar to how different buildings in the same street get unique numbers.
My building is 33 and Microsoft’s is 101 in the Wood Avenue South.
While this is enough to uniquely identify words or buildings in the same street, it is not enough to easily calculate distances globally and providing directions.
This is where the need to encode proximity information in the numbers comes in.
In the physical world this is what the GPS system does and in the NLP word that is what embeddings do.
My office latitude and longitude are 40.565070 and -74.328800, while Microsoft’s are 40.562810 and -74.327000. You can represent these two sets of numbers and two two-dimensional vectors. They are clearly in close proximity.
Similarly, when it comes to words, that is what embeddings do. Embeddings are essentially absolute coordinates in the latent space, but with hundreds of dimensions.
Similar words get clustered together while different ones are spread apart.
Let’s write some code to see how this approach makes it easy to compare similar words, even when they are not exact textual matches.
!pip install spacy
!python -m spacy download en_core_web_lg
import spacy
nlp = spacy.load(‘en_core_web_lg’)
If this step fails, try restarting the Python kernel using the green circular arrow in the toolbar.
Next, we are going to encode 4 words into vectors and compare them.
tokens = nlp(u’computer laptop mouse house’)
for token1 in tokens:
for token2 in tokens:
print(token1.text, token2.text, token1.similarity(token2))
These are the results we get.
computer computer 1.0
computer laptop 0.677216
computer mouse 0.4434292
computer house 0.3233881
laptop computer 0.677216
laptop laptop 1.0
laptop mouse 0.41455442
laptop house 0.24750552
mouse computer 0.4434292
mouse laptop 0.41455442
mouse mouse 1.0
mouse house 0.16095255
house computer 0.3233881
house laptop 0.24750552
house mouse 0.16095255
house house 1.0
You can see computer and laptop are similar while mouse and house are not.
Now, let’s review a different example.
tokens = nlp(u’I will take the Lincoln Tunnel to go to NYC. Abraham Lincoln was the 16th president of the United States’)
We are going to compare the similarity of the word Lincoln which appears in the token positions 4 and 12.
print(tokens[4].similarity(tokens[12]))
We get 1.0 which means the model considers them equivalent, but we know that is not the case as they refer to different things.
What is the problem here?
What I just described so far are context-free embeddings. They don’t consider the context where the word is used.
This is where BERT comes in and takes this concept a significant step further by introducing context-aware embeddings.
Let’s see them in action to appreciate this.
First, we need to install another package and download new embeddings.
!pip install spacy transformers
!python -m spacy download en_trf_bertbaseuncased_lg
Then, we load the BERT pretrained embeddings.
nlp = spacy.load(“en_trf_bertbaseuncased_lg”)
Now, we will repeat the same test.
tokens = nlp(u’I will take the Lincoln Tunnel to go to NYC. Abraham Lincoln was the 16th president of the United States’)
print(tokens[4].similarity(tokens[12]))
This time we get 0.5028017 which correctly indicates that while the word is the same, it doesn’t mean the same in the two sentences I provided.
Very powerful stuff!
Context-aware embeddings
BERT embeddings encode not just proximity but also the surrounding context of each word. For example, let’s review the different meanings of the word Lincoln.
Abraham Lincoln (Person)
Lincoln Navigator (Car)
Lincoln, Nebraska (City)
Lincoln Tunnel (Landmark)
The word “Lincoln” above represents completely different things and a system that assigns the same coordinates regardless of context, won’t be very precise.
If I am at my office and we want to visit “Lincoln”, I need to provide more context.
Am I planning to visit the Lincoln memorial?
Do I plan to drive all the way to Nebraska?
Am I talking about the Lincoln Tunnel?
The text surrounding the word can provide clues about what I might mean.
If you read from left to right, the word Abraham, might indicate I am talking about the person, and if you read from right to left, the word Tunnel, might indicate I am referring to the landmark.
But you’d need to read from left to right and from right to left to learn that I actually want to visit the University of Nebraska-Lincoln.
BERT works by encoding different word embeddings for each word usage and relies on the surrounding words to accomplish this. It reads the context words bidirectionally (from left to right and from right to left).
How does BERT Answer Questions?
Now that we have a solid understanding of how context-aware embeddings play a critical role in BERT success, let’s dive in into how it actually answers questions.
Question answering is one of the most complex tasks in NLP. It requires completing multiple NLP subtasks end-to-end.
BERT and similar transformers-based systems perform exceptionally well, but for the most part remain black boxes.
You provide your input and get amazing results with no visibility into how the system produced them.
Fortunately, there is growing research into “explainable AI” that hopes to understand the inner workings of these systems better.
In order to understand BERT’s performance on Question Answering, I’m going to share insights I gained from reading this paper:
How Does BERT Answer Questions? A Layer-Wise Analysis of Transformer Representations.
“There are multiple questions this paper will address:
(1) Do Transformers answer questions decompositionally, in a
similar manner to humans?
(2) Do specific layers in a multi-layer Transformer network
solve different tasks?
(3) How does fine-tuning influence the network’s inner state?
(4) Can an evaluation of network layers help determine why
and how a network failed to predict a correct answer?”
Question Answering Systems
As you saw in the code examples, current question answering systems predict the answers using three numbers: the confidence score, and the start and end index of the text span with the answer in the context.
We are going to take a closer look to understand how BERT comes up with these predictions.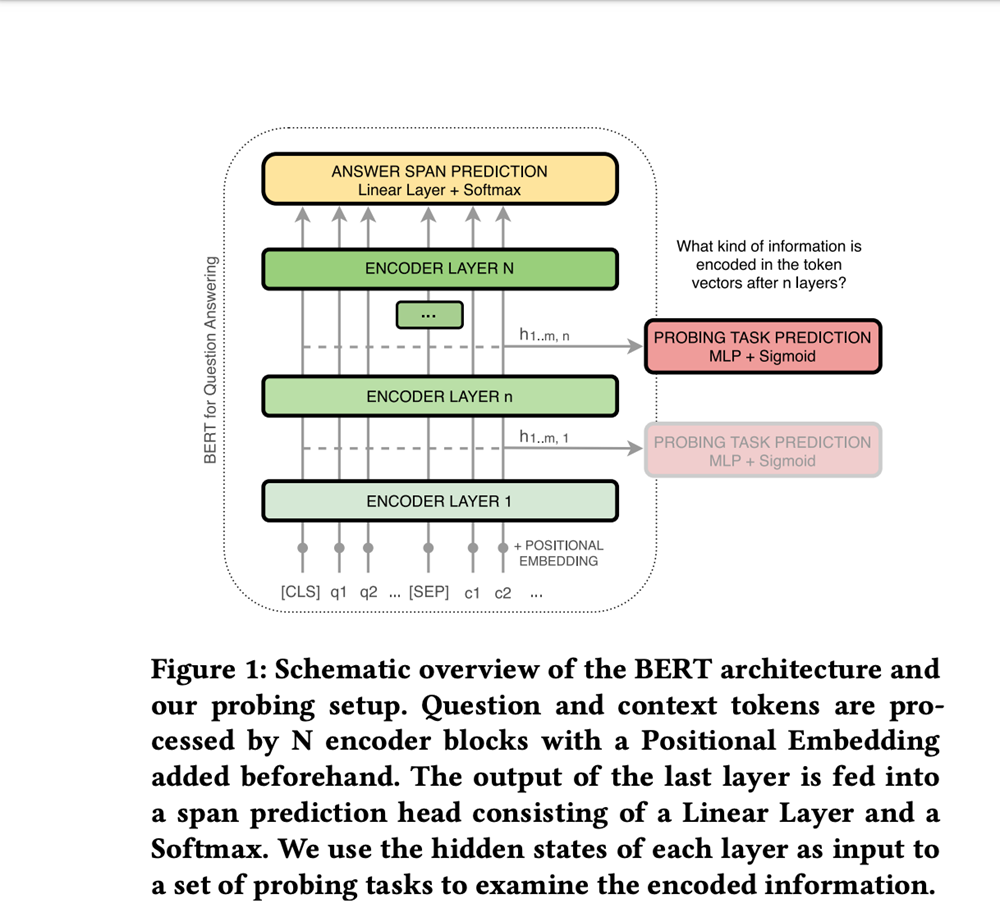
The input embeddings, in this case the question and the context, go through successive transformation layers until the answer is predicted. Each layer performs a sort of smart filtering to eliminate irrelevant embeddings and arrive at the correct answer.
The authors of the paper evaluated BERT layer transformations by focusing on five supporting NLP subtasks: Name Entity Labeling, Coreference Resolution, Relation Classification, Question Type Classification and Supporting Facts.
Their thesis was that these subtasks should help BERT get to the correct answer.
Let’s review the purpose of each subtask.
Name Entity Labeling categorizes a group of tokens as one entity, converting text to things. The researchers used 18 entity categories in their probing setup.
Coreference Resolution helps the model connect mentions in the text with the relevant entity.
Relation Classification classifies the relationship between two entities.
Question Type Classification is probably the most important subtask in a Question Answering system. This subtask classifies the input question into question types.
Supporting Facts is very important to answer complicated questions that require complementary information.
We will see examples of these subtasks in the analysis part below.
In the example above, we can see how the model can find the correct answers in the context by performing relevant subtasks.
Now, let’s see what the researchers learned.
The Phases of BERT Transformations
The following is a visual and multi-phase analysis of what happens inside the BERT layers when presented with the question “What is a common punishment in the UK and Ireland?” and the context provided in the table above.
Please remember that we are looking at what happens inside the latent space representation of the embeddings. Specifically, how they are transformed to get to the final answer layer by layer.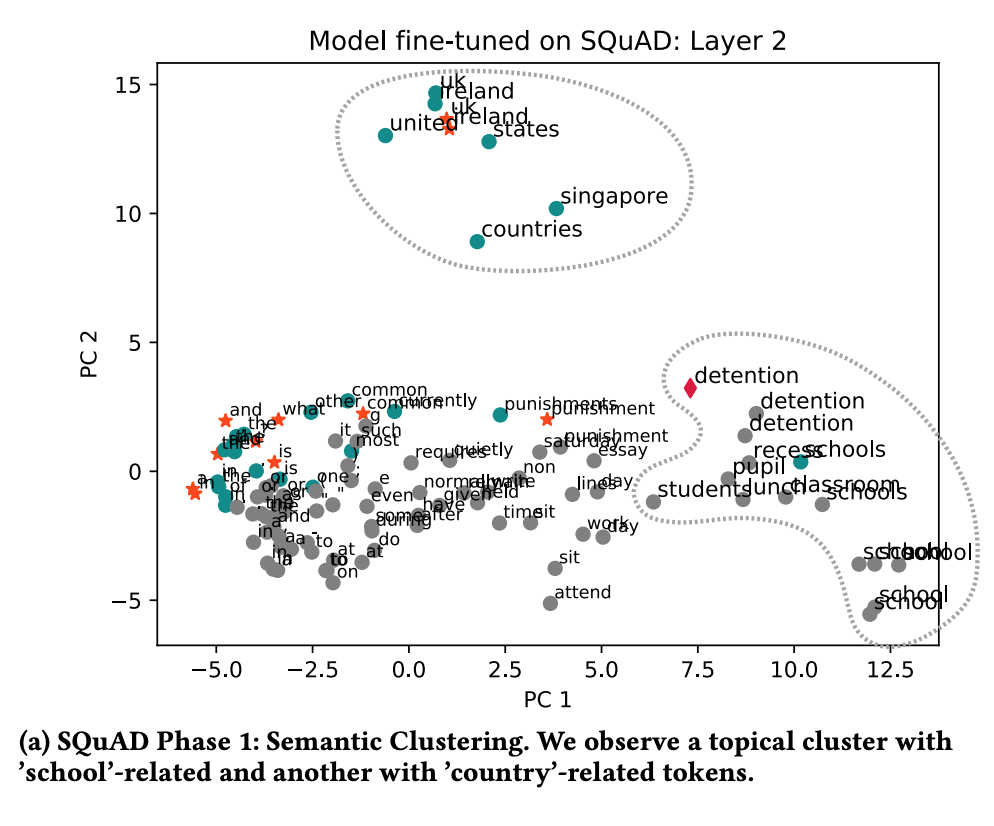
In the first phase, the researchers found that similar words are grouped together in a similar way as in the coding exercises we performed. There is nothing specific to question answering here yet.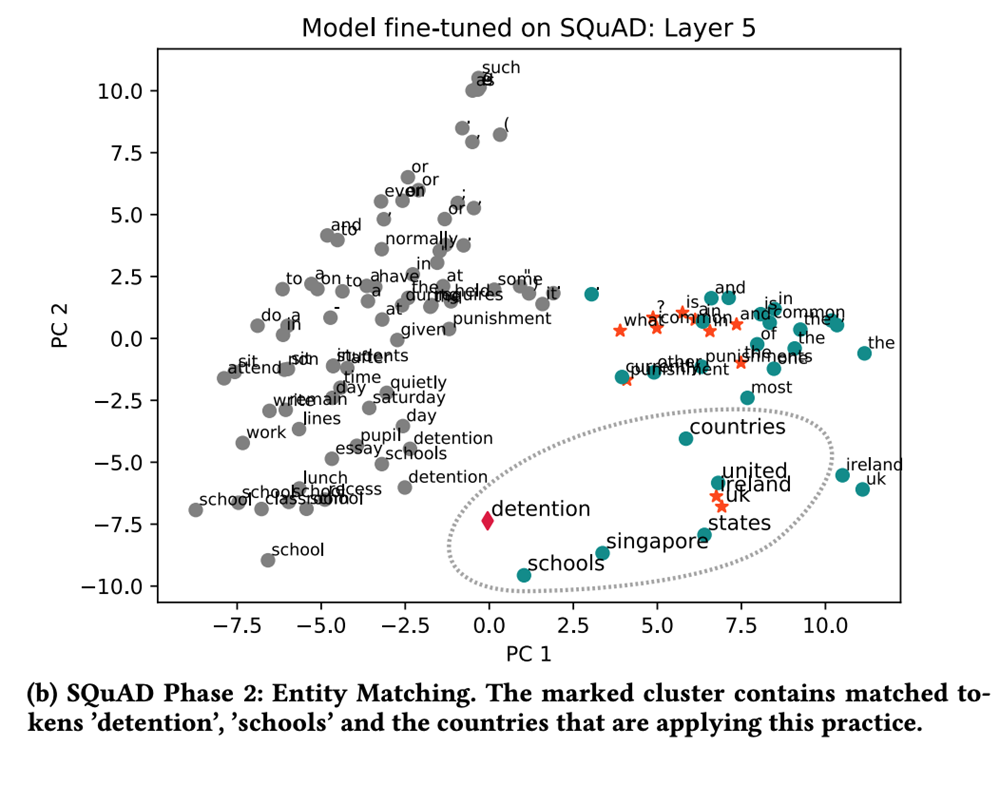
In phase 2, the researchers found evidence of entity matching where we see “detection” associated with the countries that practice it.
I was very surprised to see how fast BERT narrows down the answer.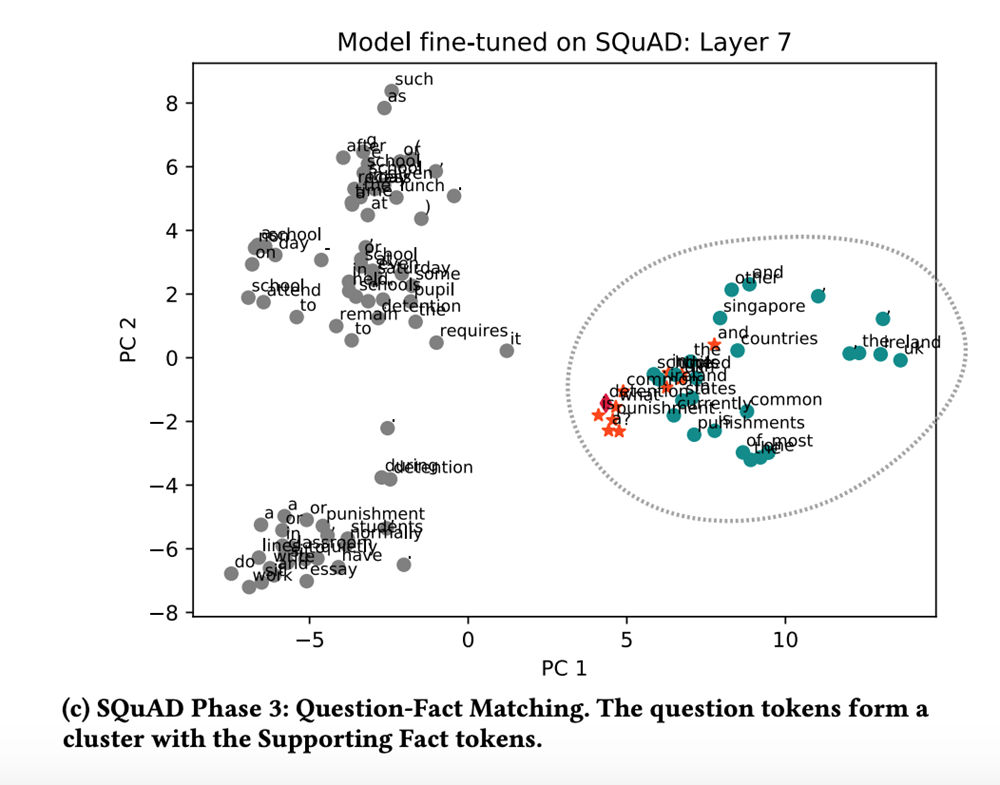
In phase 3, it appears like the model is gathering the facts to confirm it has the right answer. Very impressive.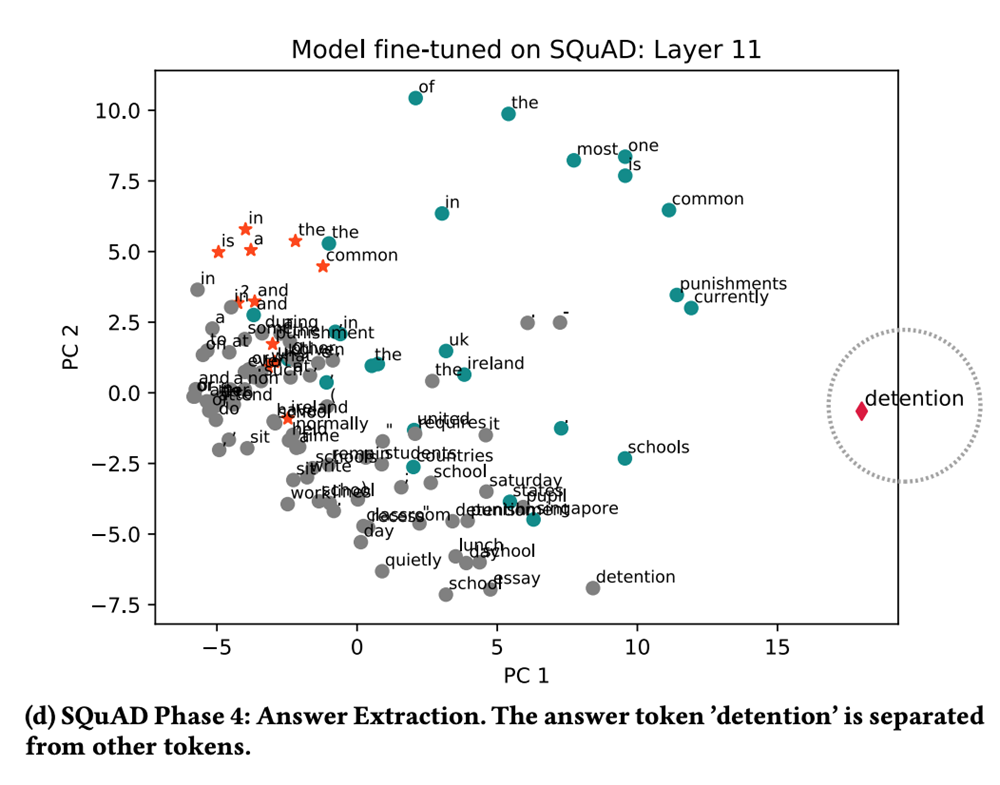
Finally, in phase 4 the correct answer is found and the confidence score is computed.
Something interesting they discovered is that the initial embeddings gain task specific knowledge as they progress through the layers in the network. This is similar to how BERT embeddings gain context during the pre-training phase.
The more information is encoded in the embeddings the stronger they perform.
There are many other papers and articles trying to explain how BERT works, but I found this paper to have the best and most intuitive explanation.
Practical Implications for SEO and Content Marketing
How can you use these insights and scripts to improve your chances of ranking for popular question searches relevant to your content?
The advances in NLP since BERT are happening at a breathtaking pace. In recent months, Microsoft researchers announced Turing-NLG. A model with 17 billion parameters, more than twice of those of the previous record holder.
The most exciting part for me is that this new model is able to answer questions directly with a full sentence, instead of highlighting the answer in the context.

There is work underway to incorporate this into Bing, Cortana and other Microsoft services.
Even with all these exciting advances, it is important to make sure that your content meets users needs first but please don’t forget about the search engines.
Use the code snippets I shared in this article against your most important content and the most popular questions asked by your users. Make sure that if you have the best answers, BERT-based answering systems can extract them.
This might require reorganizing your content a bit and/or the supporting facts by trial and error.
Here are some steps for you to consider.
- Download your search keywords from Bing Webmaster Tools and filter the ones with questions in Excel.
- Look for the ones with low Click-Through Rate (many search appearances, but few clicks)
- Type them in Bing and see if there is a competing page showing up
- Run the competing page and question through the code snippets above
- Run your page through the same
If your score is lower than expected, you might be able to update your content to improve the answer and/or the supporting facts.
Don’t obsess over the scores, but use them to guide you as you update the content to make your answers easy to extract.
___________
About the Guest Blogger: Hamlet Batista

Hamlet Batista is CEO and founder of RankSense, an agile SEO platform for online retailers and manufacturers. He holds U.S. patents on innovative SEO technologies, dumped Java for Python back in 2004, and believes great SEO results should not take 6 months.”