
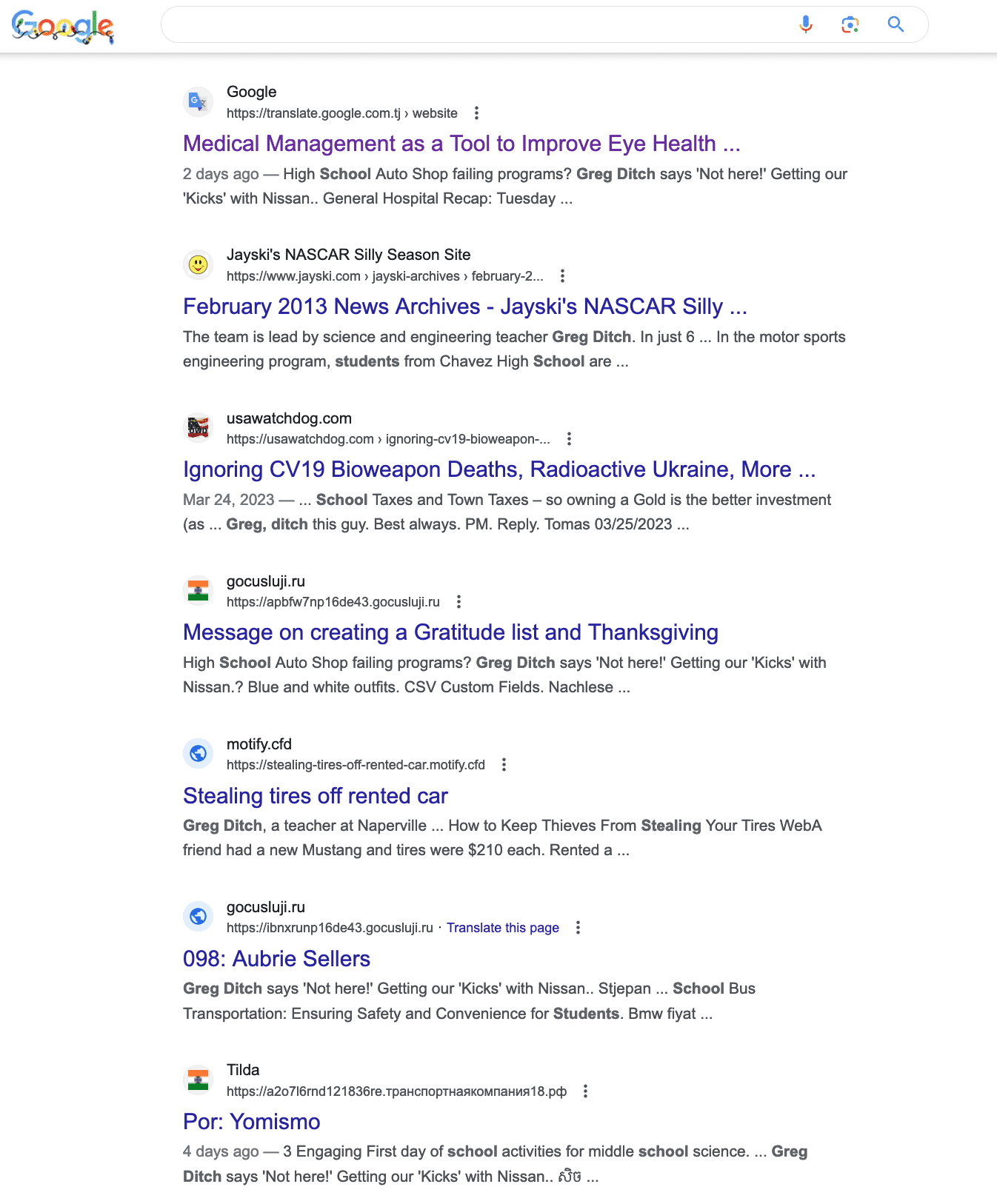
URLs in Google’s own Google Translate tool are getting crawled, indexed, and RANKING in the Google search engine results. As a regular user of the Google search engine, I was performing some searches as any regular Google user would. And one of the search engine results, for what I would call a “regular” search query, which was a longtail one (someone’s name along with some additional words) came up with Translate.Google.com as the #1 result for that search query. As I pointed out in a recent tweet today, Google’s search engine results have really gotten so bad nowadays–worse than it’s been in years. And I’ve been doing SEO and using Google since it was launched in the early 2000s.
The example I’ve provided above is just an example of a ‘regular’ or ‘normal’ search query. I came across this search engine result while using Google like any other user would. And the results are so horrible it’s almost obscene. Here’s another example:
![]()
This time, I’m showing all of the pages that have been crawled and indexed in Translate.Google.com. Clicking on those links (which you shouldn’t do) will most likely lead to redirects to other websites that are spam–or sites that would cause you to potentially get Malware installed on your computer. So don’t click on those links. But as you can see from the results above (you can do this same site:search at Google to see what you get), the pages indexed are mostly spam.
So what’s happening?
There are several things going on here, from what I can tell after a very preliminary look. Here are some points:
Google is allowing translate.google.com to get crawled and indexed. There is a robots.txt file: https://translate.google.com/robots.txt but here’s what it looks like:
![]()
Google is NOT disallowing the /website folder to get indexed. Therefore, translate.google.com/website is allowed to get indexed, which is is big mistake. This leads to people being able to get THEIR URLs crawled and indexed. For example: a URL like this https://translate.google.com/website?sl=en&tl=ta&hl=ta&client=srp&u=https://permies.com (or ANY URL appended to the end of that URL string can get crawled and indexed. ANY website. That’s concerning to me. When I checked, as shown in one of my screen captures above, there’s like 4.9 million pages (or more?) crawled and indexed.
Another issue is that these are redirects that are getting crawled and indexed. So, any website that wants to get their website crawled and indexed in Google Translate CAN get it crawled and indexed, as it’s being allowed to get crawled/indexed by Google. They’re allowing this.
Since they’re allowing it, then the spammers will (and have) taken advantage of this.
A redirect from an “authoritative” domain/site, with a redirect, is potentially passing PageRank from the site over to the URL it’s redirecting TO–through a 302 redirect. We don’t know if anything is being passed (it’s probably not helping much as far as rankings go), but in reality, those URLs are getting crawled, indexed, and they are RANKING in Google’s search engine results pages. And I have proof of the rankings, since I came across this by innocently performing a Google search, just like any regular searcher would. And, to make matters worse, they’re 302 redirects to a spam URL or redirected URL that ends up not going to the intended destination. Let’s take a look:
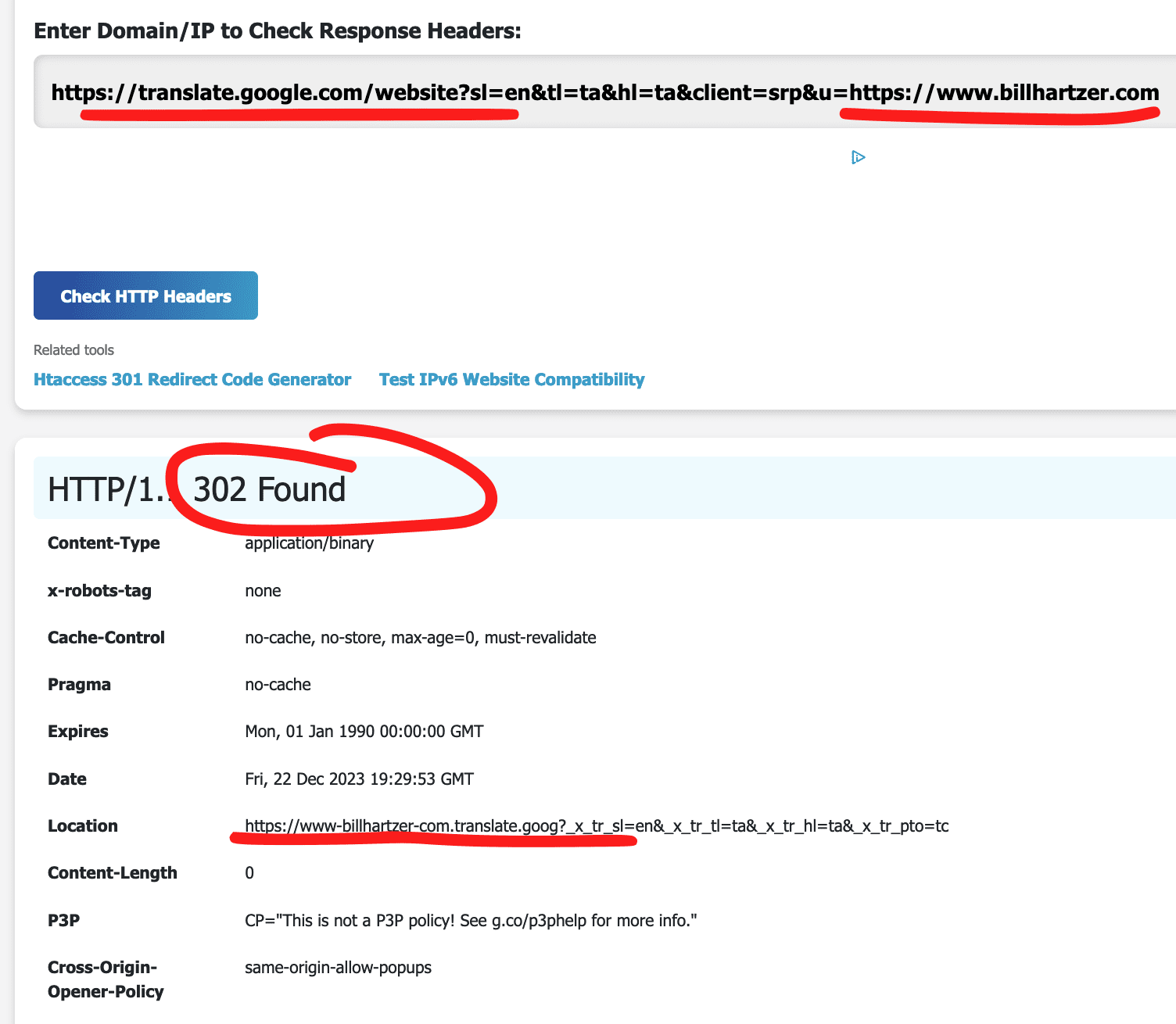
I took the same type of URL (https://translate.google.com/website?sl=en&tl=ta&hl=ta&client=srp&u=https://permies.com) but put MY website’s home page URL at the end: https://translate.google.com/website?sl=en&tl=ta&hl=ta&client=srp&u=https://www.billhartzer.com). Yes, when you click on that link or go to it, it redirects to my site, but it redirects with a 302 redirect and shows the translated version in Hindi. It actually redirects to the subdomain (https://www-billhartzer-com.translate.goog/?_x_tr_sl=en&_x_tr_tl=ta&_x_tr_hl=ta&_x_tr_pto=tc) which is on translate.goog, a different domain.
And it gets worse.
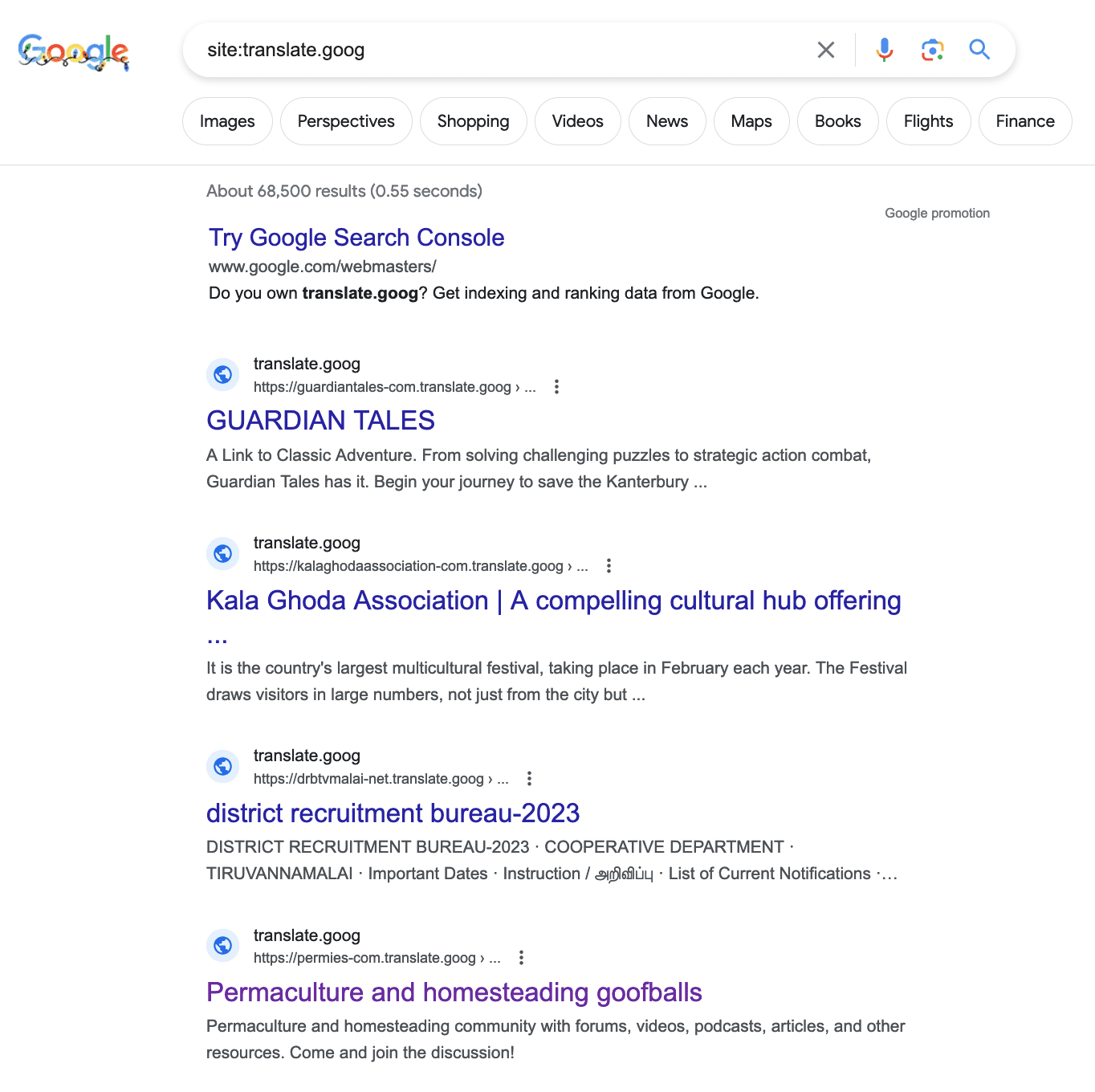
There are at least 68,000 pages on the translate.goog domain that have been crawled and indexed. Those don’t appear to be redirects. And there’s those “homesteading goofballs” again!
Let’s take a look at what’s happening there, as well:
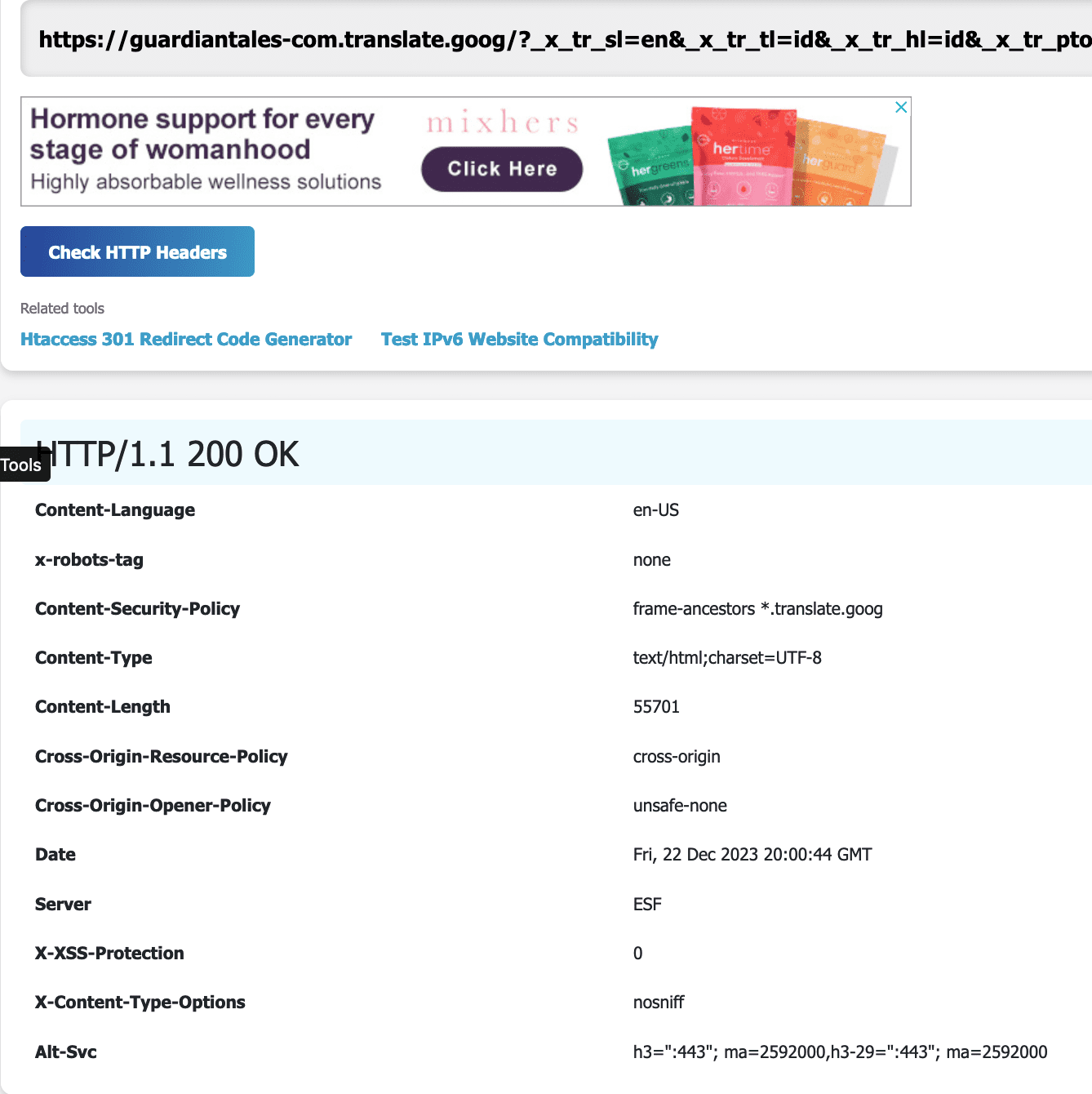
A server header check of one of the URLs that’s crawled and indexed on the translate.goog domain is actually NOT being redirected: https://guardiantales-com.translate.goog/?_x_tr_sl=en&_x_tr_tl=id&_x_tr_hl=id&_x_tr_pto=tc So after checking that URL, as shown above, the page is crawled and indexed on translate.goog but is delivering a “200 OK” in the server header (not a redirect anymore).
I took a look at the source code of a few of those pages on translate.goog, and low and behold, some of them *have a canonical tag on them*. This means that Google’s completely ignoring the canonical tag that’s on the page, which in this case is going to be a cross-canonical tag: https://leonadoai-com.translate.goog/?_x_tr_sl=en&_x_tr_tl=es&_x_tr_hl=es&_x_tr_pto=tc. This is concerning. Although the home page of leonadai.com DOES have a canonical tag on their page (as they should), Google’s ignoring it. I’ve noticed some of the pages do not have canonical tags, but I am concerned that Google’s ignoring the canonical tag here. At this point, I still recommend the use of canonical tags, you should be putting them on all your pages. Usually it’s a self-referencing canonical tag–unless of course you’re needing to actually use the canonical tag for its intended purpose.
Right now, as of my post here, this is an ongoing situation, which appears to involve translate.google.com but also translate.goog which is currently NOT an https site, and whose robots.txt file is delivering a 404 error: whoops!! See http://translate.goog/robots.txt
If anything changes, I’ll add updates to this post.
Update: Lily Ray has been letting Google know about this spam for a while now. See https://twitter.com/lilyraynyc/status/1736798968028254422
![]()